
Last August the International Congress of Egyptologists took place in Leiden. This is the biggest and most important conference for Egyptologists in the world, held every four years in either Europe or Egypt. The theme of this edition was The future of ancient Egypt, and I was happy to find there was room for workshops on AI and big data (more about that in a future post) as well as the presentation of various digital projects.
Theban Mapping Project
https://thebanmappingproject.com/
One of the projects presented was an add-on to the Theban Mapping project. After a relaunch in 2021, the website now has a mobile version and includes not just the Valley of the Kings, but the Valley of the Queens and western wadis (125 tombs added, 89 with plan). The most famous of these is of course the splendid tomb of queen Nefertari that has been extensively restored by the Getty Institute (photos of which will be added). The website furthermore contains a historical timeline, glossary and articles, making it useful for both Egyptologists and the wider public. The only thing still missing from the sweet old discontinued Theban Mapping Project website is the Theban Tomb bibliography. Fortunately it can still be accessed in archived form. I will also incorporate this data in the private tomb database I am creating for my PhD project, that will be published online once I am done (famous last words).
Thesaurus Linguae Aegyptiae
https://thesaurus-linguae-aegyptiae.de
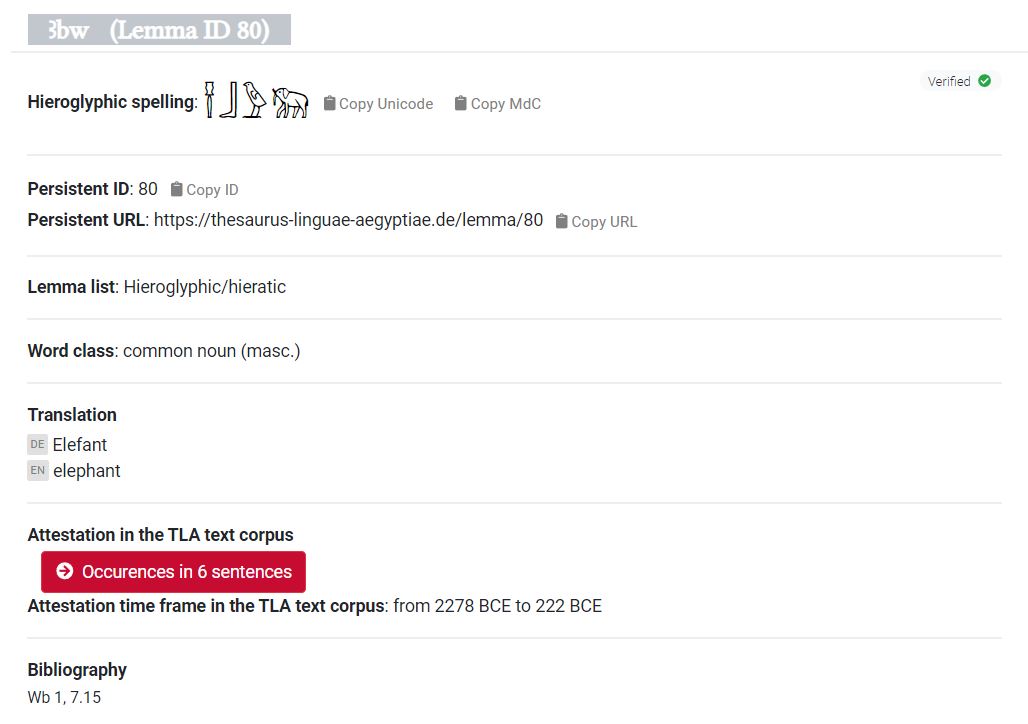
Another new project presented during the conference was the shiny new TLA or online Wörterbuch (thank you, Germans!). It is a great improvement in a number of respects, such as that it provides persistent URLs for each lemma, gives a time frame for the attestations in the corpus, and searches can be done in Manuel de Codage (e.g. ‘Abw’) or Unicode format (𓍋𓃀𓅱𓃰). For some reason, however, I didn’t manage to get the Unicode input to work yet. Also, while compiling a list of lexemes with their number of attestations in the TLA (to get an idea about the relative popularity of these words in ancient Egyptian texts), I noticed the numbers change. This, I was explained, is because sometimes lemmas are taken offline to be edited, or doubles are removed. So it’s a work in a progress, but a wonderful work in progress! I really like the design and an API is currently under development. This will be a great asset to digital Egyptologists working with large corpora of data, and (if open source) can be an inspiration for other projects.
Unicode & WebGlyph
Talking about Unicode and other digital scripts, Mark-Jan Nederhof presented some interesting Unicode developments, such as new control characters to group and overlay hieroglyphs. His presentation can be found here.
In the same session, Jan Buurman presented the hieroglyphic text processor WebGlyph, developed together with Ed de Moel. The web version is based on the Manuel de Codage and includes a tool to add new hieroglyphs, as well as a group editor. The software can be accessed here (login as guest): http://71.174.62.16/Demo/WebGlyph2
New transliteration
But the major thing to come out of the conference was the adoption of the new Leiden Unified Transliteration. After years of using different transliteration systems in each country, a secret meeting was held during the conference in a smoke-filled backroom where at long last some sensible choices were made regarding i’s, h’s, k’s and q’s. The new transliteration was then unanimously accepted by the congress. Huzzah for progress! The transliteration font has been updated accordingly.
![]()